7장 딥러닝을 시작합니다 - 패션 럭키백을 판매합니다!
인공 신경망
- 가장 기본적인 인공 신경망은 확률적 경사 하강법을 사용하는 로지스틱 회귀와 같음
- 생물학적 뉴런에서 영감을 받아 만든 머신러닝 알고리즘
- 이미지, 음성, 텍스트 분야에서 뛰어난 성능을 발휘함
텐서플로와 케라스
- 텐서플로 - 구글이 오픈소스로 공개한 딥러닝 라이브러리
- 케라스 - 텐서플로의 고수준 API
인공 신경망으로 모델 만들기
- 딥러닝 분야는 데이터셋이 충분히 커서 검증 점수가 안정적이고 교차 검증을 수행하기에는 훈련시간이 너무 오래 걸려 교차 검증을 잘 사용하지 않고 검증 세트를 별도로 덜어내어 사용함
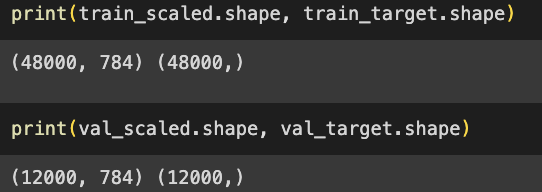
- 훈련 세트에서 20%를 검증세트로 덜어냄

- 훈련세트와 검증세트 크기
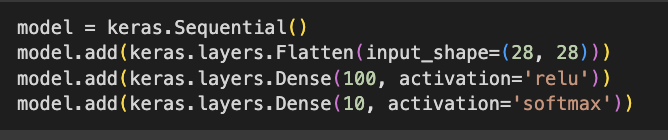
- 밀집층 생성 - 층을 양쪽의 뉴런이 모두 연결하고 있어 완전 연결층이름고도 부름

- 밀집층을 가진 신경망 모델을 생성함 - 케라스의 Sequential 클래스 사용

인공 신경망으로 패션 아이템 분류하기
- 케라스 모델 훈련 전 설정
- 손실 함수 종류 설정
- 이진 분류 : loss = ‘binary_crossentropy’
- 다중 분류 : loss = ‘categorical_crossentropy’
- 훈련 과정에서 계산하고 싶은 측정값 지정
- 원-핫 인코딩 - 정숫값을 배열에서 해당 정수 위치의 원소만 1이고 나머지는 모두 0으로 변환
- 다중 분류에서 출력층에서 만든 확률과 크로스 엔트로피 손실을 계산하기 위함
- 텐서플로에서는 ‘sparse_categorical_crossentropy’ 손실을 지정하면 이런 변환을 수행할 필요가 없음

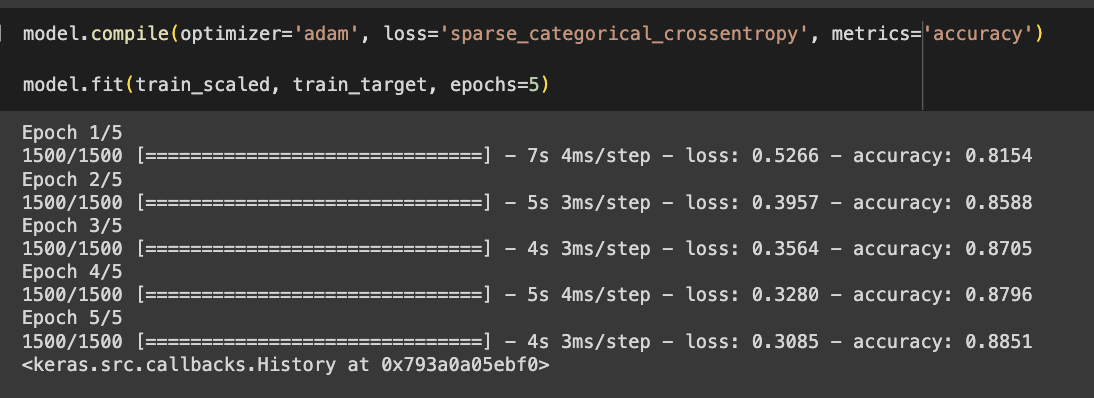
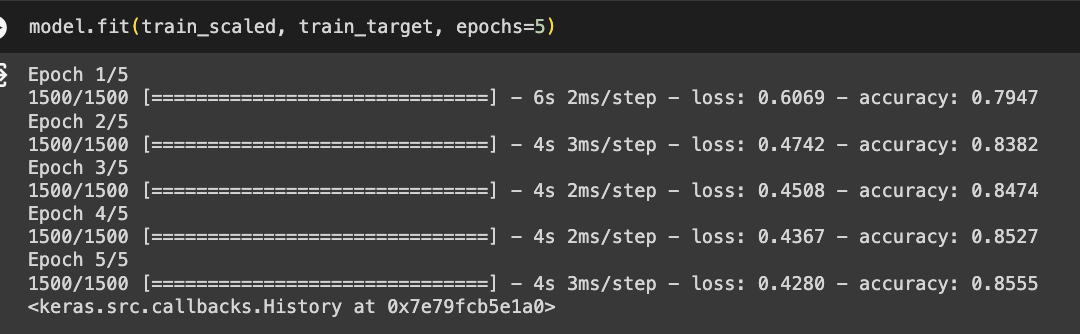
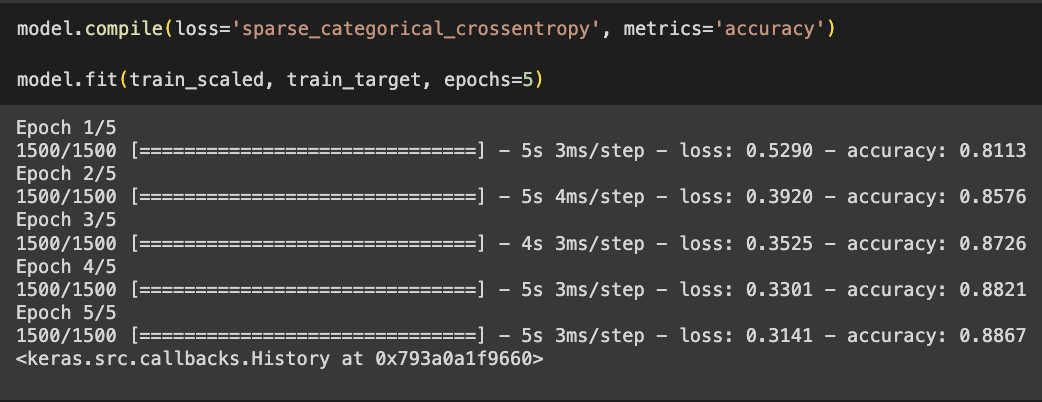
- 모델 훈련
- 케라스는 에포크마다 걸린 시간과 손실, 정확도를 출력함
- 모델 성능 평가
- 케라스는 에포크마다 걸린 시간과 손실, 정확도를 출력함

확인문제 7-1
- 인공 신경망의 입력 특성이 100개이고 밀집층에 있는 뉴런 개수가 10개일 때 필요한 모델 파라미터의 개수는 1010개
- 밀집층에 있는 10개의 뉴런이 100개의 입력과 모두 연결됨 → 10 * 100 = 1000
- 뉴런마다 1개의 절편이 있음 → 10
- 총 1010개
- sigmoid : 이진 분류라면 시그모이드 함수를 사용
- compile() : loss 매개변수로 손실함수 지정, metrics 매개변수로 측정 지표 지정
- sparse_categorical_crossentropy : 타깃값이 정수인 다중 분류일 경우 사용
심층 신경망
2개의 층
- 케라스 API를 사용하여 패션 MNIST 데이터셋을 불러옴
- 훈련세트와 검증세트를 나눔

- 입력층과 출력층 사이에 밀집층이 추가되었음
- 입력층과 출력층 사이에 있는 모든 층을 은닉층이라고 부름
- dense1→ 은닉층, dense2 → 출력층

심층 신경망 만들기
- dense1과 dense2 객체를 Sequential 클래스를 추가하여 심층 신경망을 생성

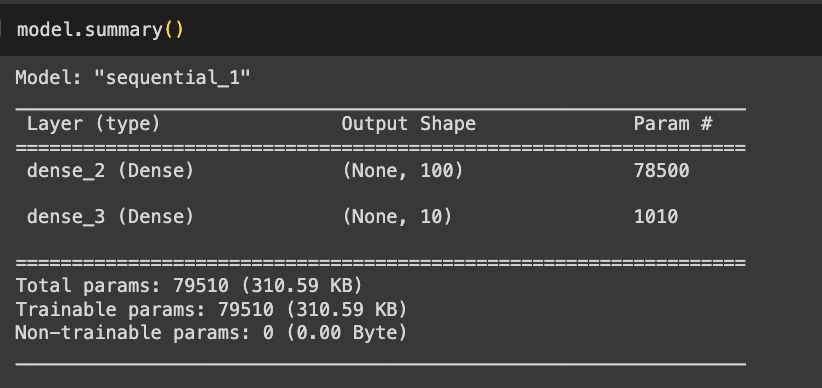
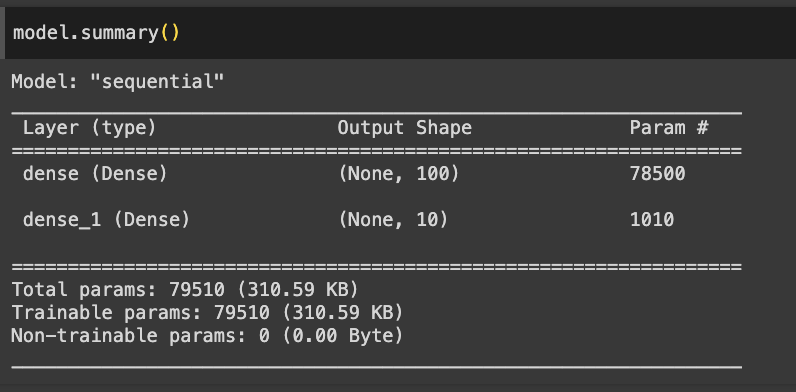
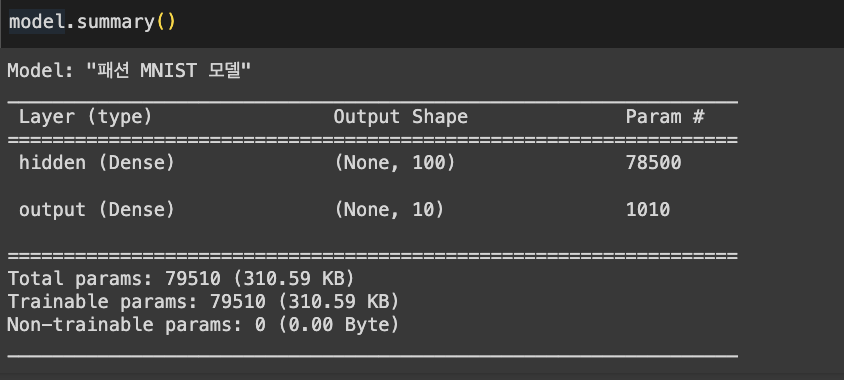
- summary를 통해 층에 대한 유용한 정보를 얻을 수 있음
- (None, 100)
- None : 샘플의 개수 →아직 정의되지 않아 None으로 출력됨
- 100 : 은닉층의 뉴런 개수
- param 78500
- 샘플마다 784개의 픽셀값이 은닉층을 통과하면서 100개의 특성으로 압축됨
- 784 * 100 + 100 (절편)
층을 추가하는 다른 방법
- Sequential 클래스의 생성자 안에서 바로 Dense 클래스의 객체를 만드는 경우
- 편리하지만 아주 많은 층을 추가하려면 Sequential 클래스 생성자가 매우 길어짐

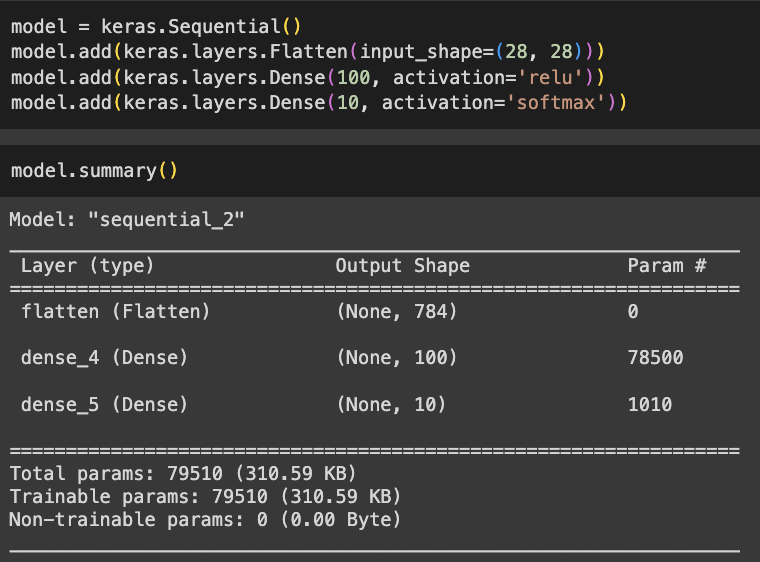
- Sequential 클래스의 객체를 만들고 이 객체의 add() 메서드를 호출하여 층을 추가함
렐루 함수
- 층이 많은 심층 신경망일수록 그 효과가 누적되어 학습을 더 어렵게 만드는데 이를 개선하기 위한 활성화 함수
- 이미지 분류 모델의 은닉층에 많이 사용
- Flatten 클래스 사용하여 층 추가
- 배치 차원을 제외하고 나머지 입력 차원을 모두 일렬로 펼치는 역할
- 입력에 곱해지는 가충치나 절편이 없음 → 인공 신경망 성능을 위해 기여하는 바는 없음
- 모델 훈련

- 시그모이드 함수를 사용했을 때와 비교하면 성능이 조금 향상됨
- 검증 세트 성능

옵티마이저
- 신경망의 가중치와 절편을 학습하기 위한 알고리즘 또는 방법
- 가장 기본적인 옵티마이저는 확률적 경사 하강법인 SGD임
- SGD 옵티마이저를 사용하려면 compile() 메서드의 optimizer 매개변수를 ‘sgd’로 지정함

- ‘sgd’ 문자열은 tensorflow.keras.optimizers 패키지 아래 SGD 클래스로 구현되어있음

- SGD 클래스의 학습률 기본값 0.01
- 변경을 하려면 learning_rate 매개변수에 지정하여 사용

- SGD 클래스의 momentum 매개변수 기본값은 0
- 0보다 큰 값을 지정하면 그레이디언트를 가속도처럼 사용하는 모멘텀 최적화를 사용함
- 보통 momentum 매개변수는 0.9 이상을 지정
- SGD 클래스의 nesterov 매개변수 기본값 False
- True 변경하면 네스테로프 모멘텀 최적화

- 적응적 학습률
- 모델이 최적점에 가까이 갈수록 학습률을 낮출 수 있음
- 안정적으로 최적점에 수렴할 가능성이 높음
- optimizer 매개변수의 기본값이 ‘rmsprop’


- Adam
- Adam 클래스의 매개변수 기본값을 사용해 패션 MINIST 모델 훈련
- 검증 세트 성능
확인문제 7-2
- model.add(keras.layers.Dense(10,. activation=’relu’)): Dense 클래스의 객체를 전달해야함
- Flatten : 치 차원을 제외하고 나머지 입력 차원을 모두 일렬로 펼침
- relu : 이미지 처리 작업에 널리 사용되는 렐루 함수
- SGD : 기본 경사 하강법과 모멘텀, 네스트로프 모멘텀 알고리즘을 구현할 클래스